韓国のデータの入手方法 [ゲノム解析で古代史]
Genome1000プロジェクトのデータには、フリーで使えるVCFファイルがあるのですが、日本も中国もベトナムもあるのに、なぜか韓国がありません。
最近、フリーで入手できるサイトを見つけたので報告します。
![[iモード]](https://blog.ss-blog.jp/_images_e/108.gif) KoreanGenome.org
KoreanGenome.org
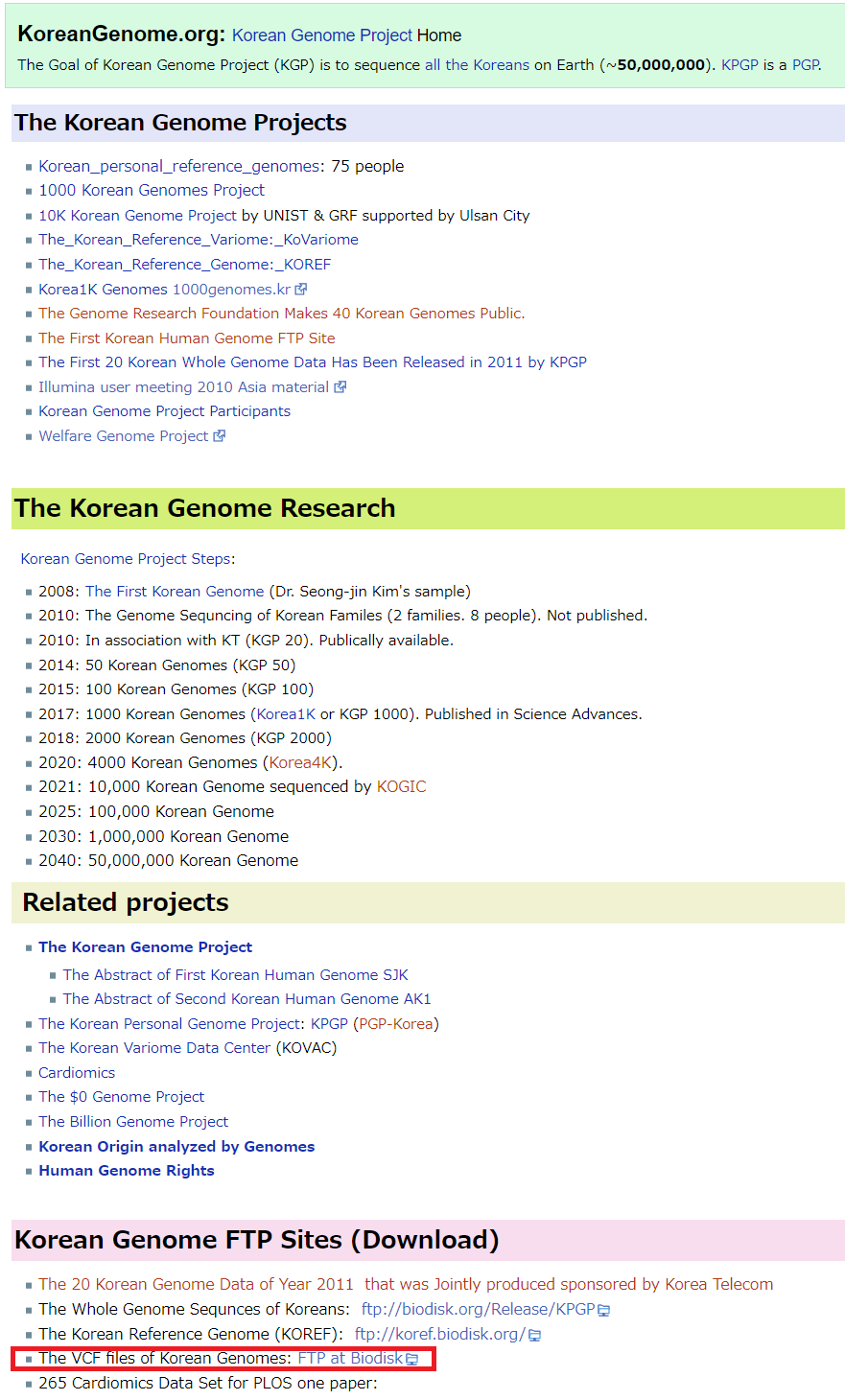
※下から2行目のThe VCF files of Korean Genomes: FTP at Biodiskに注目!
なお、このサイトのリンクは、
・ftp://biodisk.org/Release/KPGP/
KPGP_Data_2014_Release_Candidate/WGS_VCF/
となっていますが、最新版は、
・ftp://biodisk.org/Release/KPGP/
KPGP_Data_2019_Release_Candidate/
WGS_SR_VCF_91_KOREAN_JOINT_CALL/
の「chrX.snv.recalibrated.vcf」のようです。
サイズは1-3GB程度ですので、なんとかダウンロード可能でした![[るんるん]](https://blog.ss-blog.jp/_images_e/146.gif)
最近、フリーで入手できるサイトを見つけたので報告します。
※下から2行目のThe VCF files of Korean Genomes: FTP at Biodiskに注目!
なお、このサイトのリンクは、
・ftp://biodisk.org/Release/KPGP/
KPGP_Data_2014_Release_Candidate/WGS_VCF/
となっていますが、最新版は、
・ftp://biodisk.org/Release/KPGP/
KPGP_Data_2019_Release_Candidate/
WGS_SR_VCF_91_KOREAN_JOINT_CALL/
の「chrX.snv.recalibrated.vcf」のようです。
サイズは1-3GB程度ですので、なんとかダウンロード可能でした
2022-03-02 22:38
コメント(0)
趣味のゲノム解析【実践編2】 [ゲノム解析で古代史]
前回の続きです。
VCFファイルから「血液型」を調べる方法について書いておきます。
ABO血液型の遺伝子は第9染色体にあり、そのSNP(塩基の変異のこと…A/T/G/C)は次の2つです。
・rs8176746 (C→A型/A→B型)
・rs8176719 (del[なし]→O型/G→rs8176746の型)
ただし、人間の染色体は2本で1組(2倍体)なので、↑のSNPはそれぞれ2個ずつあります。
![[本]](https://blog.ss-blog.jp/_images_e/70.gif) ABO Blood Type and Personality Traits in Healthy Japanese Subjects
ABO Blood Type and Personality Traits in Healthy Japanese Subjects
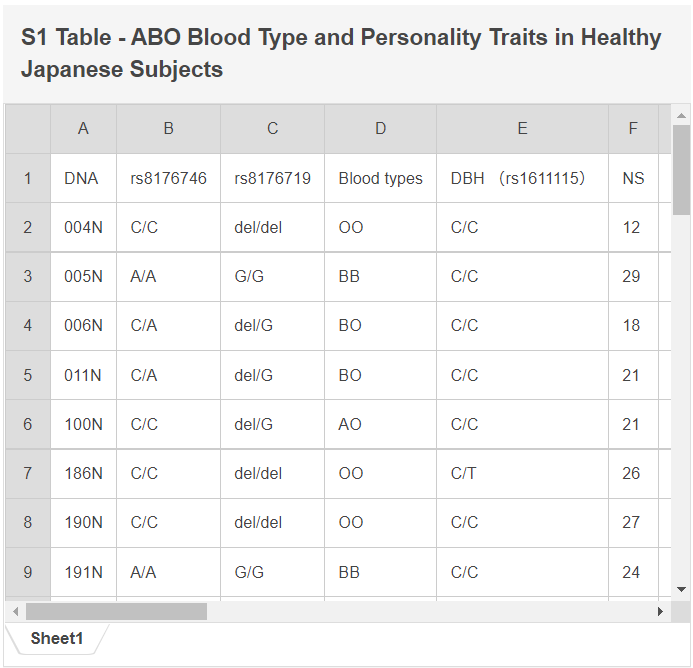
つまり、VCFファイルに格納されているSNPの内容を解読すれば、その人の血液型がわかるのです!
ただし、一部のVCFファイルの情報にはrs番号がなく、POS(位置情報)だけの場合があり、そのときは該当するPOSを検索する必要があります。
やり方は↓のとおりです。
jMORP Genomic Variants

実際に調べてみたところ、
・rs8176746→POS 136131322
・rs8176719→POS 136132908
となりました。
しかし、現実のVCFファイルは巨大なので、特定のSNPのデータだけ取り出すのは簡単ではありません。
VCFファイルの実体は、TAB区切りのCSVファイルなので、Excelで読み取ること自体は可能です。
ただし、Excelの上限の100万行以上になると、取り扱いは相当大変です。
私は、ツールを探すのが面倒だったので、CsvDivNetというソフトを使ってVCFファイルを分割し、Excelで該当する番号の行を切り出しました。
結果は↓のとおりです。
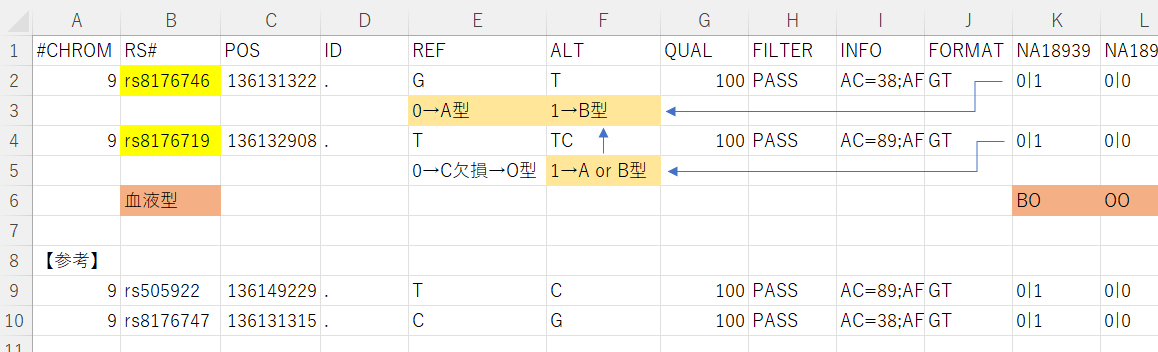
※一般的には「rs8176746 (C→A型/A→B型)」ですが、なぜかこのVCFファイルでは、C→G(Cのペアになる塩基)、A→T(Aのペアになる塩基)が表示されます。これは、rs8176719も同じで、G→C(Gのペアになる塩基)でした。
なんで?
面白かったのは、rs8176746はA型が標準(REF)、rs8176719はO型が標準(同)と決められていることです。欧米人が基準なので、そうなるんでしょうね![[わーい(嬉しい顔)]](https://blog.ss-blog.jp/_images_e/140.gif)
VCFファイルから「血液型」を調べる方法について書いておきます。
ABO血液型の遺伝子は第9染色体にあり、そのSNP(塩基の変異のこと…A/T/G/C)は次の2つです。
・rs8176746 (C→A型/A→B型)
・rs8176719 (del[なし]→O型/G→rs8176746の型)
ただし、人間の染色体は2本で1組(2倍体)なので、↑のSNPはそれぞれ2個ずつあります。
つまり、VCFファイルに格納されているSNPの内容を解読すれば、その人の血液型がわかるのです!
ただし、一部のVCFファイルの情報にはrs番号がなく、POS(位置情報)だけの場合があり、そのときは該当するPOSを検索する必要があります。
やり方は↓のとおりです。
実際に調べてみたところ、
・rs8176746→POS 136131322
・rs8176719→POS 136132908
となりました。
しかし、現実のVCFファイルは巨大なので、特定のSNPのデータだけ取り出すのは簡単ではありません。
VCFファイルの実体は、TAB区切りのCSVファイルなので、Excelで読み取ること自体は可能です。
ただし、Excelの上限の100万行以上になると、取り扱いは相当大変です。
私は、ツールを探すのが面倒だったので、CsvDivNetというソフトを使ってVCFファイルを分割し、Excelで該当する番号の行を切り出しました。
結果は↓のとおりです。
※一般的には「rs8176746 (C→A型/A→B型)」ですが、なぜかこのVCFファイルでは、C→G(Cのペアになる塩基)、A→T(Aのペアになる塩基)が表示されます。これは、rs8176719も同じで、G→C(Gのペアになる塩基)でした。
なんで?
面白かったのは、rs8176746はA型が標準(REF)、rs8176719はO型が標準(同)と決められていることです。欧米人が基準なので、そうなるんでしょうね
2022-03-02 22:07
コメント(0)



