「疑似科学とされるものの科学性評定サイト」の科学性評定《驚くべき投稿と回答・続》 [Gijika.com]
またもや「疑似科学とされるものの科学性評定サイト」に思わず目![[目]](https://blog.ss-blog.jp/_images_e/84.gif) を疑うような投稿と回答が掲載されました。
を疑うような投稿と回答が掲載されました。
【注:意味がわかりにくかったようなので一部に修正・追記を行いました】
サンプル数が小さい場合には、統計分析が有効で一般化できるかどうか(と解釈しましたが…)という質問と回答です。
正直に白状しますが、最初読んだときには、この投稿と回答の意味が全く理解できませんでした。![[たらーっ(汗)]](https://blog.ss-blog.jp/_images_e/163.gif)
次は、投稿のポイントと思われる文章です。
【投稿】
こちらの投稿でもABO FANが私の研究を否定し、自己成就予言が起こっていないこと、思い込みにより有意な主効果が出たのではないことの根拠としている金澤正由樹著「統計でわかる血液型人間学入門」に関して、皆様のご意見をお聞かせいただきたいと思い投稿しました。
(長いので途中省略)
各血液型40名にも満たない調査対象者の平均正答率を、「その血液型の性格特性を知っている割合」の指標として一般化できるのか管理人様をはじめ、このサイトをご覧の皆様のご意見を伺いたいと思います。
(投稿者:山岡重行,投稿日時:2016/05/28 16:34:46)
次は、回答のポイントと思われる文章です。
【回答】
個人的には、一般化するにはかなり幼いデータと思います。
(回答日時:2016/05/28 22:58:27)
その後しばらく考えたのですが、どうやら、「文系的発想」による文章だと考えると、素直に意図が理解できるようです。
そもそも、統計的検定は、サンプル数が小さくともある程度の結論を出すための手段です。
つまり、「統計分析が有効」かどうかは、自分で(帰無)仮説を立てて検証すればいいはずで(例えば金澤さんの間違いを証明するような…)、その仮説が何も書いてないなら読者は判断も理解もしようがありません。![[がく~(落胆した顔)]](https://blog.ss-blog.jp/_images_e/142.gif)
投稿と回答の両方に、「皆様のご意見を伺いたい」という意味の文章がありますから、投稿者の山岡重行さんも、回答者の管理者さんも(帰無)仮説が立てられないということなのでしょうか?
もちろん、金澤正由樹さんの結論が有効なもの(=一般化できる)かどうか、「疑似科学とされるものの科学性評定サイト」の面々が疑問を抱くのはもっともですし、この疑問が正当なものであることも疑いはありません。
しかし、自分たちで金澤さんの結論に反論できず(?)に、そのことを公開してまで意見を求めてまでするというのは、はたして好ましいことなのでしょうか…。
私は、サイトの信頼性(特に統計学)に疑問を抱かせるような行動を取るべきではないと思うんですが。
#仮に私がこのサイトの管理者だったら、金澤さんなんか無視すると思います(苦笑)。
【注:意味がわかりにくかったようなので一部に修正・追記を行いました】
サンプル数が小さい場合には、統計分析が有効で一般化できるかどうか(と解釈しましたが…)という質問と回答です。
正直に白状しますが、最初読んだときには、この投稿と回答の意味が全く理解できませんでした。
次は、投稿のポイントと思われる文章です。
【投稿】
こちらの投稿でもABO FANが私の研究を否定し、自己成就予言が起こっていないこと、思い込みにより有意な主効果が出たのではないことの根拠としている金澤正由樹著「統計でわかる血液型人間学入門」に関して、皆様のご意見をお聞かせいただきたいと思い投稿しました。
(長いので途中省略)
各血液型40名にも満たない調査対象者の平均正答率を、「その血液型の性格特性を知っている割合」の指標として一般化できるのか管理人様をはじめ、このサイトをご覧の皆様のご意見を伺いたいと思います。
(投稿者:山岡重行,投稿日時:2016/05/28 16:34:46)
次は、回答のポイントと思われる文章です。
【回答】
個人的には、一般化するにはかなり幼いデータと思います。
(回答日時:2016/05/28 22:58:27)
その後しばらく考えたのですが、どうやら、「文系的発想」による文章だと考えると、素直に意図が理解できるようです。
そもそも、統計的検定は、サンプル数が小さくともある程度の結論を出すための手段です。
つまり、「統計分析が有効」かどうかは、自分で(帰無)仮説を立てて検証すればいいはずで(例えば金澤さんの間違いを証明するような…)、その仮説が何も書いてないなら読者は判断も理解もしようがありません。
投稿と回答の両方に、「皆様のご意見を伺いたい」という意味の文章がありますから、投稿者の山岡重行さんも、回答者の管理者さんも(帰無)仮説が立てられないということなのでしょうか?
もちろん、金澤正由樹さんの結論が有効なもの(=一般化できる)かどうか、「疑似科学とされるものの科学性評定サイト」の面々が疑問を抱くのはもっともですし、この疑問が正当なものであることも疑いはありません。
しかし、自分たちで金澤さんの結論に反論できず(?)に、そのことを公開してまで意見を求めてまでするというのは、はたして好ましいことなのでしょうか…。
私は、サイトの信頼性(特に統計学)に疑問を抱かせるような行動を取るべきではないと思うんですが。
#仮に私がこのサイトの管理者だったら、金澤さんなんか無視すると思います(苦笑)。
本題に戻ります。
上の質問に対しては、教科書に書かれているような模範解答があるわけではありません。
しかし、原点に戻って考えれば、少しでも真実に近づくことは可能です。
面白い課題なので、私なりに考えてみました。
さて、サンプル数が小さい場合は、二択のアンケート結果にどの程度の誤差が生じるのでしょうか?
問題となっている調査対象者(X軸)の全サンプルは102人(4種類の血液型全員)ですから、1つの血液型当たりだと約25人です。
2つの選択肢のどちらも同じく回答したとすると、回答の標準偏差σは、0.5×0.5×25=6.25の平方根2.5をサンプル数25で割ればいいので、0.1=10%になります。
結局、誤差はどのぐらいを見積もればいいのでしょうか?
普通は95%の信頼区間(±1.96σ)を使うのですが、いくらなんでもこれは基準が厳しすぎるでしょう。
なぜなら、今回問題となっているデータには、8つのサンプルがあるからです。
後述※するように、傾向を見るだけなら、8つのデータの全てに95%の信頼性は必要ありません。
そこで、少々甘い(かなり甘い![]() )といわれるかもしれませんが、誤差は±1σ(標準偏差)とします。
)といわれるかもしれませんが、誤差は±1σ(標準偏差)とします。
言い換えれば、全体の68.3%まではこのレンジ(±1σ)に入ることになります。
※8つのサンプルがすべて金澤さんの結論を否定する方向に動く確率は、5%=0.05の8乗になりますので極端に小さい確率になります。8つのサンプル全体で95%=0.95の信頼性だとすると、1つのサンプルでは0.95の8乗である0.66まで誤差は許容できます。.[H28.8.22追記]
また、投稿と回答にはありませんが、他の血液型との差(Y軸)の誤差はどの程度を考えればいいのでしょうか?
こちらはサンプルがかなり多いのですが、t分布の両側検定で全体の68.3%という数値がわかりません。面倒なのでt=1.0まで許容するということにします。
#片側検定でp=0.25ならt=0.674(df=∞)、p=0.1ならt=1.282(df=∞)
すると、こちらは全サンプルが1300649人[H28.8.22訂正]、標準偏差は最大1.3ぐらいなので、誤差は0.1(2.5%)※ぐらい見ておけば十分のようです。
※1.3÷√(160+160)/(160×160)=0.1 [160は各血液型の平均人数 H28.8.22追記]
これで準備ができました。
金澤さんのグラフに、実測値の誤差の範囲(推定値)がわかるように赤の円を付け加えてみました。
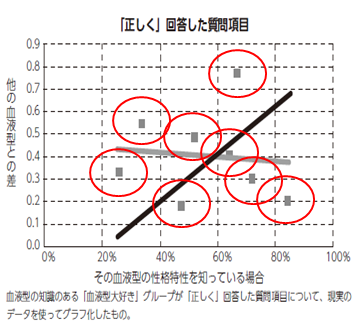
赤の円が重なっている領域は、全体からみると大した面積ではありませんから、全体の傾向を変えるほどの影響はあるとは考えられません。
つまり、統計的な誤差を考慮しても、現実のデータの傾向は、その性格特性を知っているかどうかと、他の血液型との回答の差(=統計的な差)は関係ないということです。
結局、「統計的な差は“思い込み”によるものではない」という金澤さんの結論は変更する必要はないものと思われます。
いかがでしょうか?
【追記】
念のため、上に書いた2項分布の標準偏差、信頼性区間、t検定 etc.は、大学で学ぶ統計学の基礎・基本です。
統計学の単位を取ったなら、手持ちの教科書で確認してもいいし、そうでなければネットで検索すればいくらでも資料が出てきます。
疑似科学批判者が、わざわざ「皆様のご意見を伺いたい」と質問するような内容ではないと思うんですが。![]()
また、他の分野(例えば医学)なら、サンプル40人はそれほど珍しくないはずです。
2016-05-29 16:37
コメント(0)
トラックバック(0)




コメント 0